
一、概述
在日常的开发与办公环境中,快速定位特定文件及内容的需求十分普遍。尤其在处理大规模文件时,高效搜索成为提升工作效率的关键。本文将详细解析一款基于PyQt6开发的文件搜索工具。该工具不仅支持按文件后缀筛选和关键字匹配,还提供实时搜索结果展示及详细信息导出功能,可显著优化用户对文件的管理效率。
该工具的核心优势体现在四个方面:首先,通过多线程技术实现后台搜索,避免界面卡顿;其次,兼容UTF-8、GBK等主流编码格式确保文件内容的准确读取;再者,搜索结果同步更新至界面,用户可即时查看匹配项;最后,完善的导入导出功能支持结果存档或后续分析。
二、功能使用详解
1. 文件夹选取与搜索条件设置
启动工具后,用户需指定目标路径并设置搜索规则。若想搜索文本或日志文件,可在后缀栏输入 ".txt;.log" 进行多格式限定。引入拖拽功能后,用户只需将文件夹拖入输入框,无需手动输入路径,操作体验更加便捷。
2. 文件内容智能搜索
当用户确认搜索条件后,程序会启动独立线程执行文件遍历与关键字匹配。该过程同时检查文件名和内容完整性,采用多层编码尝试确保不同格式文件的准确解析。搜索进度实时显示,用户可同步操作界面其他功能。匹配结果将以树状结构展示文件路径、名称及大小等核心信息。
3. 单文件深度分析
针对单个文件的精准搜索需求,工具开设专项入口。用户可指定具体文件路径,输入需匹配的文字,系统将逐行扫描并列出包含关键字的语句。此功能特别适用于开发者调试源代码或排查文本内容异常时的快速定位。
4. 结果管理和数据导出
搜索完成后,工具会自动统计匹配文件数量、关键语句行数及耗时。用户可通过右侧列表查看完整匹配记录。支持将结果文件列表导出为文本文件,或导出当前搜索所得的文件路径结构。历史数据可通过导入功能复现,进一步增强工具的灵活性。
5. 文件结构信息管理
工具提供树状结构的导入功能,允许用户载入之前记录的文件路径信息。导入后,数据立即显示在界面上并可直接使用,例如继续执行更高层级筛选或追加搜索条件,有效提升重复任务处理效率。
三、技术实现解析
1. 多线程架构设计
程序核心采用PyQt6的QThread实现多线程交互。SearchWorker类独立处理文件扫描与内容匹配,通过信号更新文件树数据。FileReader类负责文件内容分析,二者协同工作确保主线程流畅运行。这一架构使用户在执行长时间文件扫描时仍能自由操作其他功能。
2. 文件解码策略
为确保跨编码文件的兼容性,工具设计了三级编码尝试机制。当打开文件时,系统依次使用utf-8、gbk、latin-1编码解析,自动选择成功格式进行内容读取。这种冗余设计显著提升了工具对特殊编码文件的处理成功率。
3. 数据交互增强
文件导出功能包含结果列表和树结构两种模式。结果列表精确记录关键行内容,而树形结构导出完整保存文件元数据。导入模块采用分段解析策略,将通过制表符分隔的文本快速重构为TreeView控件的展示形式,有效保持数据完整性。
class SearchWorker(QThread):
update_file = pyqtSignal(dict)
finished = pyqtSignal()
def __init__(self, folder, extensions, keyword):
super().__init__()
self.folder = folder
self.extensions = extensions
self.keyword = keyword
def run(self):
for root, _, files in os.walk(self.folder):
if not self.running:
break
for file in files:
if any(file.endswith(ext) for ext in self.extensions):
path = os.path.join(root, file)
if self.file_contains_keyword(path, self.keyword):
size = os.path.getsize(path)
self.update_file.emit({
"name": file,
"size": self.format_size(size),
"path": path
})
self.finished.emit()
def file_contains_keyword(self, path, keyword):
for encoding in ['utf-8', 'gbk', 'latin-1']:
try:
with open(path, 'r', encoding=encoding) as f:
return any(keyword in line for line in f)
except (UnicodeDecodeError, Exception):
continue
return False
四、运行效果演示
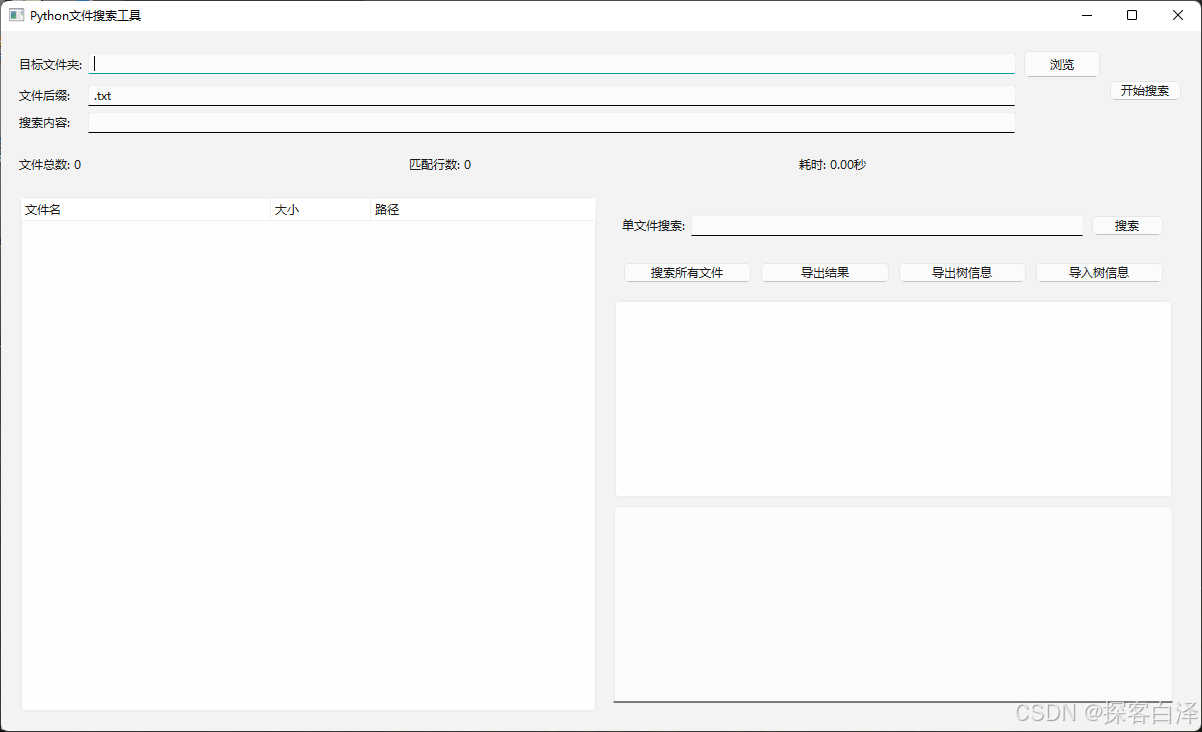

五、完整源代码
[此处因篇幅限制展示核心代码框架,完整实现需结合详细逻辑]
def export_match_list(self):
keyword = self.keyword_input.text().strip() or "search"
timestamp = time.strftime("%Y%m%d_%H%M%S")
filename = f"{keyword}_{timestamp}.txt"
desktop = "D:/桌面/"
path = os.path.join(desktop, filename)
with open(path, 'w', encoding='utf-8') as f:
for i in range(self.match_list.count()):
f.write(self.match_list.item(i).text() + "\n")
QMessageBox.information(self, "导出完成", f"文件已保存到:{path}")
六、总结与展望
这款基于PyQt6技术栈构建的文件搜索工具,成功实现了需求中的关键功能。未来计划从三个方面优化:首先是引入进度条增强操作可视化反馈;其次考虑增加正则表达式匹配功能拓展应用场景;最后将开发批量文件操作模块,如重命名或权限管理,进一步释放开发者的时间价值。工具的模块化设计使得后续扩展空间充足,可灵活适配多样化需求。