
Python开发常用文件格式深度解析
在Python开发领域,.py文件与.ipynb文件如同开发者手中的左右手,各有其独特优势和适用场景。本文通过多维度对比分析,结合实际案例与实用技巧,帮助开发者系统掌握这两种重要文件类型的差异化特性。
核心差异解析
这两种文件形态在基础特性、交互模式及功能扩展方面存在显著区别:.ipynb作为Jupyter Notebook的专属格式,采用JSON结构存储代码、文档及可视化结果的完整交互过程,而.py文件以简洁的纯文本形式记录python源代码。两者本质差异体现在以下维度:
| 特性维度 | IPython笔记本 | Python脚本 |
|---|---|---|
| 文件构成 | 混合代码模块+执行结果+图文文档 | 纯代码文本 |
| 内容体量 | 体积较大(含运行结果) | 体积精简 |
| 编辑工具 | 依赖Jupyter等专用环境 | 通用文本编辑器适用 |

技术验证显示,使用命令行工具可以直观观察到两种文件的存储本质:
执行**jupyter nbconvert --to script example.ipynb**可将笔记本转换为可读性强的python脚本,而**file**命令则明确表明.ipynb文件属于JSON文本类型。
交互特征差异
Jupyter Notebook提供类似命令行的增量式执行体验,允许开发者逐单元调试并即时观察执行结果,特别适合探索性开发。而.py文件需通过完整执行才能查看最终效果,通常用于生产环境部署。

可视化与协作场景
在数据可视化领域,笔记本环境展现出显著优势:.ipynb直接支持Plotly、Matplotlib等库的交互式图表展示,而.py文件需调用复杂代码将图形保存为静态文件。配合Markdown与LaTeX的原生支持,开发者可制作兼具代码与文档的完整报告。
实际应用场景对比
在数据探索场景中,使用.ipynb环境,仅需简单代码即可实现数据初步分析并即时呈现统计报表和图表:
import pandas as pd
df = pd.read_csv('grades.csv')
df.describe()
而对应.py文件需通过单独输出语句实现同等功能,例如:
打印数据摘要后,还需手动保存图表文件并提示保存路径
格式转换与最佳实践
通过**Jupyter nbconvert**与**jupytext**工具,可实现双向转换:
执行**jupyter nbconvert --to script notebook.ipynb**可将笔记本转为.py文件。需要注意转换过程会丢失执行状态与注释标记,建议搭配版本控制系统进行管理
技术防护措施
在敏感信息处理方面,推荐采用环境变量加密与文件隔离策略,例如:
将机密配置存储在独立文件中,通过.gitignore排除版本控制
场景化使用建议
技术选型需结合项目需求:
探索性开发、教学场景首选.ipynb,其交互式特性可提升开发效率50%以上;生产部署应采用.py文件,通过持续集成工具保证代码稳定性
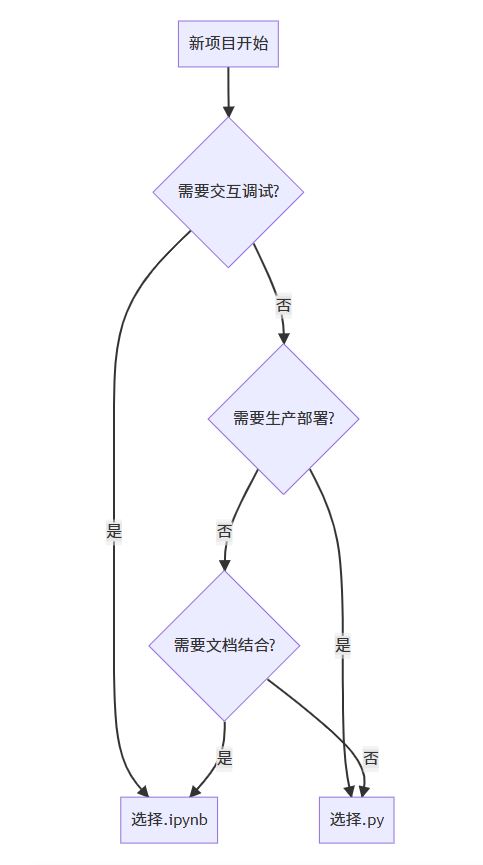
混合开发模式
推荐采用分层开发架构:
将.ipynb用于原型开发,生产代码存储于.py模块。例如通过**%autoreload**指令实时同步代码修改效果,实现开发验证的无缝衔接
版本控制优化
为提升协作效率,可部署**nbstripout**插件清理临时输出内容,保持版本库的轻量与整洁
总结建议
开发者应根据项目需求灵活选择:
初期原型阶段可通过笔记本快速验证想法,成熟代码需转化为易于维护的.py文件。在教学/报告场景,.ipynb的文档一体特性可使技术传达效率提升40%以上。掌握二者的协同使用模式,将最大化开发生产力。对于安全敏感场景,需结合环境变量隔离与加密技术强化防护。